
How to guarantee your single computation task is guaranteed to failover in case of node failures in apache Ignite ?
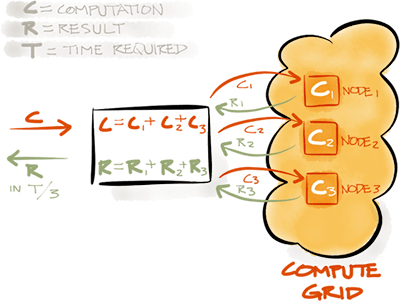
As you know failover support in apache ignite for computation tasks is only covered for master slave jobs where slave nodes will do computations then reduce back to the master node , and in case of any failure in slave nodes where slave jobs are executing , then it that failed slave job will fail over to another node to continue execution .
Ok what about if I need to execute just single computation task and I need to have failover guarantee due may be it is a critical task that do financial data modification or must finished task in an acceptable status (Success or Failure) , how we can do that ? it is not supported out of the box by Ignite but we can have a small design extension using Ignite APIs to cover the same , HOW ?
Code reference is hosted into my github :
https://github.com/Romeh/failover-singlejob-ignite

Here is the main steps from the overview above via the following flow :
1- You need to create 2 partitioned caches , one for single jobs reference and one for node Ids reference , you should make those caches backed by persistence store in production if you need to survive total grid crash
2- Define jobs cache after put interceptor to set the node id which is the primary owner and triggerer of that compute task
3- Define nodes cache interceptor to intercept after put actions so it can query for all pending jobs for that node id then submit them again into the compute grid with affinity
4- Enable event listening for node left and node removal in the grid to intercept node failure
Then let us run the show , imagine you have data and compute grid of 2 server nodes :
a- you trigger a job in node 1 which will do sensitive action like financial action and you need to be sure it is finished with a valid state whatever the case
b- what if that primary node 1 crashed , what will happen to that compute task , without the extension highlighted above it will disappear with the wind
c- but with that failover small extension , Node 2 . will catch an event that Node 1 left , then it will query jobs cache for all jobs that has that node id and resubmit them again for computation , optimal case if you have idempotent actions so it can be executed multiple times or use job checkpointing for saving the execution state to resume from the last saved point
Job data model for Jobs cache where we mark node id an ignite SQL queryable indexed field :
How the ignite failed nodes cache interceptor is implemented :
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| mport org.apache.ignite.Ignite; | |
| import org.apache.ignite.IgniteCache; | |
| import org.apache.ignite.cache.CacheInterceptorAdapter; | |
| import org.apache.ignite.cache.query.SqlQuery; | |
| import org.apache.ignite.cluster.ClusterNode; | |
| import org.apache.ignite.resources.IgniteInstanceResource; | |
| import org.jetbrains.annotations.Nullable; | |
| import javax.cache.Cache; | |
| import static com.romeh.failover.demo.CacheNames.ICEP_JOBS; | |
| public class NodesInterceptor extends CacheInterceptorAdapter<String, String> { | |
| @IgniteInstanceResource | |
| Ignite ignite; | |
| private transient IgniteCache<String, Job> jobs; | |
| private final String sql = "nodeId = ?"; | |
| private transient SqlQuery<String, Job> affinityKeyRequestSqlQuery; | |
| @Nullable@Override | |
| public void onAfterPut(Cache.Entry<String, String> entry) { | |
| // sample compute task that can be sensitive and it need to have fail over support | |
| QueryTask task = new QueryTask(); | |
| // get partitioned jobs cache reference | |
| jobs = ignite.cache(ICEP_JOBS.name()); | |
| // get the current local node reference | |
| ClusterNode clusterNode = ignite.cluster().localNode(); | |
| System.out.println("intercepting for Node failure and retry from node id : "+ clusterNode.id().toString()+" to node id : "+entry.getValue()); | |
| // Create query to get pending jobs for that node id and submit them again | |
| affinityKeyRequestSqlQuery= new SqlQuery<>(Job.class, sql); | |
| affinityKeyRequestSqlQuery.setArgs(entry.getValue()); | |
| jobs.query(affinityKeyRequestSqlQuery).forEach(affinityKeyJobEntry -> { | |
| System.out.println("found a pending jobs for node id: "+entry.getValue() +" and job id: "+affinityKeyJobEntry.getKey()); | |
| // submit again the jobs for re-execution | |
| ignite.compute().withTimeout(5500) | |
| .affinityRunAsync(ICEP_JOBS.name(),affinityKeyJobEntry.getKey(), | |
| ()->task.execute(affinityKeyJobEntry.getValue().request)); | |
| }); | |
| } | |
| } |
How the ignite jobs cache interceptor is implemented :
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import org.apache.ignite.Ignite; | |
| import org.apache.ignite.cache.CacheInterceptorAdapter; | |
| import org.apache.ignite.cluster.ClusterNode; | |
| import org.apache.ignite.resources.IgniteInstanceResource; | |
| import org.jetbrains.annotations.Nullable; | |
| import javax.cache.Cache; | |
| import static com.romeh.failover.demo.CacheNames.ICEP_JOBS; | |
| public class JobsInterceptor extends CacheInterceptorAdapter<String, Job> { | |
| @IgniteInstanceResource | |
| Ignite ignite; | |
| @Nullable@Override | |
| public void onAfterPut(Cache.Entry<String, Job> entry) { | |
| // sample sensitive computation task | |
| QueryTask queryTask=new QueryTask(); | |
| // get current node reference to get its node id | |
| ClusterNode clusterNode = ignite.cluster().localNode(); | |
| System.out.println("intercepting for job action triggering and setting node id : "+ clusterNode.id().toString()); | |
| //store node id in the job wrapper object | |
| entry.getValue().setNodeId(clusterNode.id().toString()); | |
| //create async computation with specific timeout with affinity to the jobs data cache to have collocated computation | |
| ignite.compute().withTimeout(5500) | |
| .affinityRunAsync(ICEP_JOBS.name(),entry.getKey(), | |
| ()->queryTask.execute(entry.getValue().getRequest())); | |
| } | |
| } |
Apache ignite config :
Enable Node removal and failure events listening ONLY as enabling too much events will cause some performance overhead:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <?xml version="1.0" encoding="UTF-8"?> | |
| <!– | |
| _________ _____ __________________ _____ | |
| __ ____/___________(_)______ /__ ____/______ ____(_)_______ | |
| _ / __ __ ___/__ / _ __ / _ / __ _ __ `/__ / __ __ \ | |
| / /_/ / _ / _ / / /_/ / / /_/ / / /_/ / _ / _ / / / | |
| \____/ /_/ /_/ \_,__/ \____/ \__,_/ /_/ /_/ /_/ | |
| Copyright (C) GridGain Systems. All Rights Reserved. | |
| Licensed under the Apache License, Version 2.0 (the "License"); | |
| you may not use this file except in compliance with the License. | |
| You may obtain a copy of the License at | |
| http://www.apache.org/licenses/LICENSE-2.0 | |
| Unless required by applicable law or agreed to in writing, software | |
| distributed under the License is distributed on an "AS IS" BASIS, | |
| WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | |
| See the License for the specific language governing permissions and | |
| limitations under the License. | |
| –> | |
| <!– | |
| Ignite Spring configuration file. | |
| –> | |
| <beans xmlns="http://www.springframework.org/schema/beans" | |
| xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" | |
| xmlns:util="http://www.springframework.org/schema/util" | |
| xsi:schemaLocation=" | |
| http://www.springframework.org/schema/beans | |
| http://www.springframework.org/schema/beans/spring-beans-2.5.xsd | |
| http://www.springframework.org/schema/util | |
| http://www.springframework.org/schema/util/spring-util-2.0.xsd"> | |
| <bean class="org.apache.ignite.configuration.IgniteConfiguration"> | |
| <!– Set to true to enable grid-aware class loading for examples, default is false. –> | |
| <property name="peerClassLoadingEnabled" value="false"/> | |
| <property name="publicThreadPoolSize" value="16"/> | |
| <property name="systemThreadPoolSize" value="8"/> | |
| <property name="asyncCallbackPoolSize" value="16"/> | |
| <property name="metricsLogFrequency" value="0"/> | |
| <property name="clientMode" value="false"/> | |
| <!– Enable events for examples. –> | |
| <property name="includeEventTypes"> | |
| <util:list> | |
| <util:constant static-field="org.apache.ignite.events.EventType.EVT_NODE_LEFT"/> | |
| <util:constant static-field="org.apache.ignite.events.EventType.EVT_NODE_FAILED"/> | |
| </util:list> | |
| </property> | |
| <!– Explicitly configure TCP discovery SPI to provide list of initial nodes. –> | |
| <property name="discoverySpi"> | |
| <bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"> | |
| <property name="ipFinder"> | |
| <!– Uncomment multicast IP finder to enable multicast-based discovery of initial nodes. –> | |
| <!–<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder">–> | |
| <bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder"> | |
| <property name="addresses"> | |
| <list> | |
| <!– In distributed environment, replace with actual host IP address. –> | |
| <value>127.0.0.1:47500..47509</value> | |
| </list> | |
| </property> | |
| </bean> | |
| </property> | |
| </bean> | |
| </property> | |
| <property name="binaryConfiguration"> | |
| <bean class="org.apache.ignite.configuration.BinaryConfiguration"> | |
| <property name="compactFooter" value="false"/> | |
| </bean> | |
| </property> | |
| <property name="cacheConfiguration"> | |
| <list> | |
| <bean id="ICEP_JOBS_config" class="org.apache.ignite.configuration.CacheConfiguration"> | |
| <!– Setting up basic cache parameters –> | |
| <property name="name" value="ICEP_JOBS"/> | |
| <property name="cacheMode" value="PARTITIONED"/> | |
| <property name="rebalanceMode" value="ASYNC"/> | |
| <property name="interceptor"> | |
| <bean class="com.romeh.failover.demo.JobsInterceptor"></bean> | |
| </property> | |
| <property name="indexedTypes"> | |
| <list> | |
| <value>java.lang.String</value> | |
| <value>com.romeh.failover.demo.Job</value> | |
| </list> | |
| </property> | |
| </bean> | |
| <bean id="ICEP_NODES_config" class="org.apache.ignite.configuration.CacheConfiguration"> | |
| <!– Setting up basic cache parameters –> | |
| <property name="name" value="ICEP_NODES"/> | |
| <property name="cacheMode" value="PARTITIONED"/> | |
| <property name="rebalanceMode" value="ASYNC"/> | |
| <property name="interceptor"> | |
| <bean class="com.romeh.failover.demo.NodesInterceptor"></bean> | |
| </property> | |
| </bean> | |
| <bean id="ICEP_REQUEST_DATA_config" class="org.apache.ignite.configuration.CacheConfiguration"> | |
| <!– Setting up basic cache parameters –> | |
| <property name="name" value="ICEP_REQUEST_DATA"/> | |
| <property name="cacheMode" value="PARTITIONED"/> | |
| <property name="rebalanceMode" value="ASYNC"/> | |
| <property name="indexedTypes"> | |
| <list> | |
| <value>java.time.LocalDateTime</value> | |
| <value>com.romeh.failover.demo.Request</value> | |
| </list> | |
| </property> | |
| </bean> | |
| </list> | |
| </property> | |
| </bean> | |
| </beans> |
Main App tester :
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import org.apache.ignite.*; | |
| import org.apache.ignite.events.DiscoveryEvent; | |
| import org.apache.ignite.events.EventType; | |
| import javax.cache.expiry.CreatedExpiryPolicy; | |
| import javax.cache.expiry.Duration; | |
| public class NodeApp { | |
| public static void main(String[] args) throws Exception { | |
| // just for demo and test purpose , you should design more generic bootstrap logic to start your node | |
| Ignite ignite = Ignition.start("config/igniteFailOver.xml"); | |
| try { | |
| IgniteCache<String, Job> cache = ignite.cache(CacheNames.ICEP_JOBS.name()); | |
| // enable that ONLY for one node and after you start see the system outs , you can kill that node to see the fail over logic in the second node | |
| // in production quality use logging instead of system out for sure, just i am sing it for demo limited needs | |
| System.out.println("start of jobs creation"); | |
| /* for (int i = 0; i <= 25; i++) { | |
| String key = i + "Key"; | |
| // start creating jobs by inserting them into the | |
| cache.put(key | |
| , Job.builder().nodeId(ignite.cluster().localNode().id().toString()). | |
| request(Request.builder().requestID(key).modifiedTimestamp(System.currentTimeMillis()).build()). | |
| build()); | |
| }*/ | |
| // listen globally for all nodes failed or removed events | |
| ignite.events().localListen(event -> { | |
| DiscoveryEvent discoveryEvent = (DiscoveryEvent) event; | |
| System.out.println("Received Node event [evt=" + discoveryEvent.name() + | |
| ", nodeID=" + discoveryEvent.eventNode() + ']'); | |
| ignite.compute().runAsync(() -> { | |
| IgniteCache<String, String> nodes = ignite.cache(CacheNames.ICEP_NODES.name()); | |
| String failedNodeId = discoveryEvent.eventNode().id().toString(); | |
| // only one NODE will manage to insert successfully as it it is an atomic operation and thread safe | |
| nodes.withExpiryPolicy(new CreatedExpiryPolicy(Duration.ONE_HOUR)).putIfAbsent(failedNodeId, failedNodeId); | |
| }); | |
| return true; | |
| }, EventType.EVT_NODE_LEFT, EventType.EVT_NODE_FAILED); | |
| } catch (Exception e) { | |
| // just for test , do not do that in production code | |
| e.printStackTrace(); | |
| } | |
| } | |
| } |
Testing flow :
1- first run the first ignite server node with that code commented out :
2- then run the second server node but before doing it , uncomment the highlighted code above which simulate creating now jobs for computation by inserting them into the jobs cache
3- once you run the second node , after 5 seconds kill it by shutting it down once you see it started to submit jobs from the code you just uncommented, like:
intercepting for job action triggering and setting node id : f0920c5b-3655–4e85-aa60-f763a9eb1111
Executing computation logic for the request0Key
4- you will see in the first still running node a message that highlight it received and event about the removal of the second node which from it , it will fetch the node id , then insert it on the failed nodes cache where its cache interceptor will intercept the after put action , use the node id and query in jobs cache for still pending jobs that has the same node id and resubmit them again for execution in the compute grid and here we are happy that we caught the non finished jobs from the failed crashed primary node that submitted those jobs
Received Node event [evt=NODE_LEFT, nodeID=TcpDiscoveryNode [id=2da3e806–72e3–415b-acd3–07b7da0eabe0, addrs=[0:0:0:0:0:0:0:1%lo0, 127.0.0.1, 192.168.1.169], sockAddrs=[/192.168.1.169:47501, /0:0:0:0:0:0:0:1%lo0:47501, /127.0.0.1:47501], discPort=47501, order=2, intOrder=2, lastExchangeTime=1510666504589, loc=false, ver=2.3.1#20171031-sha1:d2c82c3c, isClient=false]]
and you will see it is fetching pending jobs and submitting it again, for example you will see the following in the IDEA console:
found a pending jobs for node id: c2a32b7d-1420–4e1a-8ca2-b7080e91dc22 and job id: 19Key
Executing the expiry post action for the request19Key
References :
- Apache Ignite : https://apacheignite.readme.io/docs
- Code reference is hosted into my github : https://github.com/Romeh/failover-singlejob-ignite

nice article to understand the primary node job cover
LikeLiked by 1 person
thanks for your feedback , let me know if u need more information
LikeLike
i would like to see a an example about integration between spring boot and Apache ignite , thx a lot
LikeLike