Now here we will share some possible designs when you use the spring boot event sourcing toolkit starter plus some remarks and action points .
What are some possible designs using the toolkit for event sourcing and CQRS services :
Using the toolkit with Apache ignite and Kafka for event streaming :
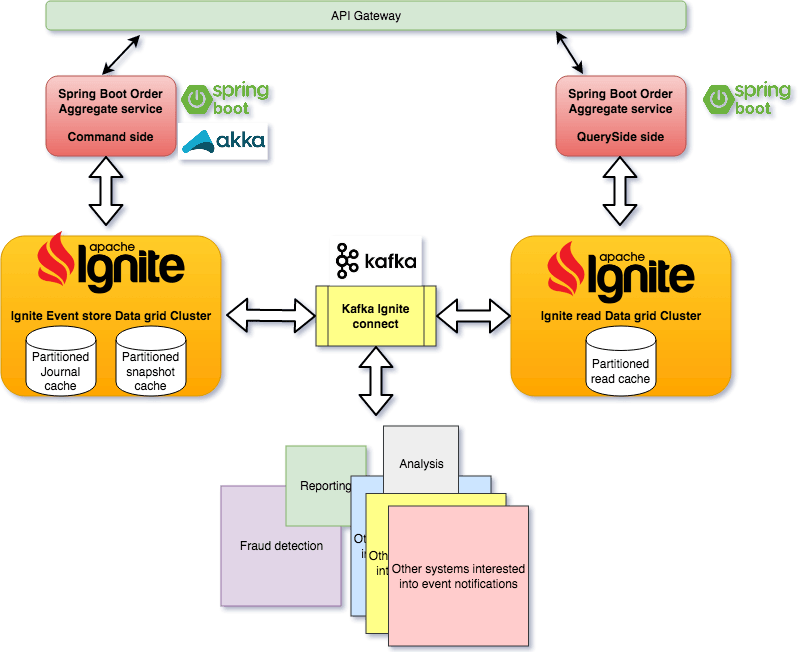
Here we do the following :
- We use the event sourcing toolkit starter to define the domain write service that will be act as the command side plus we can benefit from Spring Cloud if you will need to support micro-services architecture
- The read side application can have different data model for the query needs
- We use Apache Ignite data grid as the event store which can be easily scaled by adding more server nodes and you can benefit from the data grid rich features to some computations , Rich SQL query support plus we will use the Apache ignite continuous query to push new added events to kafka.
- We do integration between Apache and Kafka via Kafka connect to read the new added events from the events cache and stream that to the read side application and any other interested application like Fraud detection , reporting …ect.
- Infrastructure structure : Akka Cluster , Ignite cluster , Kafka Cluster Plus Service orchestration like kubernetes .
Using the toolkit with Apache Cassandra :

Here we do the following :
- We use the event sourcing toolkit starter to define the domain write service that will be act as the command side plus we can benefit from Spring Cloud if you will need to support micro-services architecture
- We use Cassandra as the event sore
- We can keep use Kafka connect to stream events to other systems for read query and other analysis and reporting needs.
- Infrastructure structure : Akka cluster , Cassandra Cluster , Kafka Cluster Plus Service orchestration like kubernetes .
Using the toolkit with Apache Ignite only:
If you application does not need all those complexisities and just small sized service you use Ignite only with the toolkit to implement the Write and Read side of your CQRS and event sourcing application .
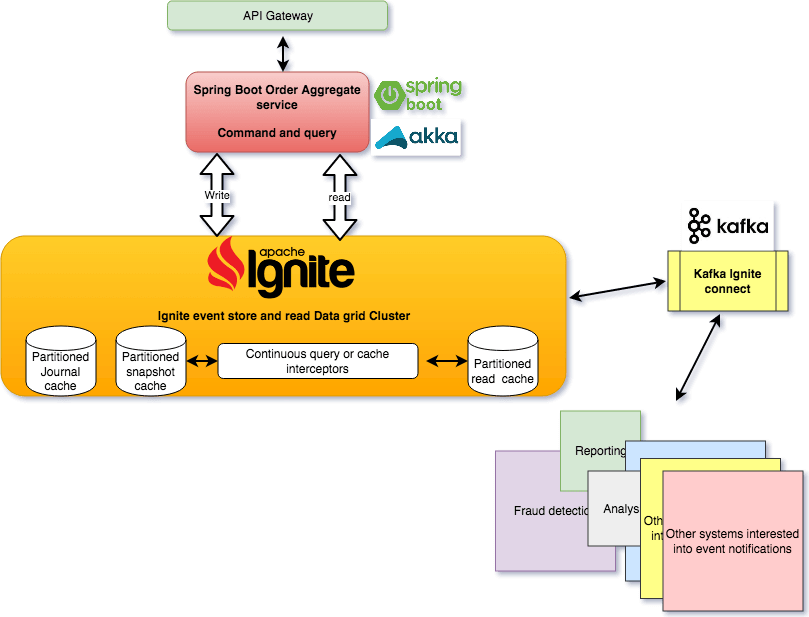
- We use the event sourcing toolkit starter to define the domain write service that will be act as the command side plus we can benefit from Spring Cloud if you will need to support micro-services architecture
- We use the Ignite data grid for event store and for query read projection by using the continuous query or cache interceptors to push the new added event to another cache with the target read model
- You can separate the read and write caches into 2 different cluster groups.
- You can still use Kafka Connect to stream events to other systems if you like
Using the toolkit with Apache Ignite and Kafka Streams:

- We use the event sourcing toolkit starter to define the domain write service that will be act as the command side plus we can benefit from Spring Cloud if you will need to support micro-services architecture
- We use Apache Ignite for the event store with Kafka connect to stream the events
- We use Kafka streams to implement the read side
Off-course there are many other designs , I just shared some in the blog here now we need to summarize some remarks and actions points to be taken into consideration
Summary notes:
- Event sourcing and CQRS is not a golden bullet for every need , use it properly when it is really needed and when it fit the actual reasons behind it
- You need to have distributed tracing and monitoring for your different clusters for better traceability and error handling
- With Akka persistance , you need to cover the following when using it for your domain entities :
- Use split brain resolver when using Akka clustering to avoid split brains and to have a predictable cluster partitioning behavior. Few useful links
- Make sure to not use Java serialization as it is really bad for your performance and throughput of your application with Akka persistence
- Need to think through about active-active model for cross cluster support due to the cluster sharding limitation with that but it is covered in the next points below
- When it comes to Active-Active support model for your application , you have multiple options for active active data center support which will come with latency and performance impact , nothing is for free anyhow:
- Akka persistence active active model support extension which is an commercial add on : Akka-Persistance-Active-Active
- If you use Apache ignite as your event store , you have 2 options :
- You can use a backing store for your data grid that support cross data center replication for example Cassandra
- You can use GridGain cross data center replication feature which is the commercial version of Apache ignite
- You can use Kafka cluster cross data center replication to replicate your event data cross multiple data centers .
- If you use Cassandra as event store , you can use cross data center replication feature of Cassandra
- At the end you need to think through about how you can will handle active-active model for your event sourced entities and all its side effects with state replication and construction especially if you use Akka persistence which most likely will not be supported without the commercial add-on or implement your solution as well for that.
Hoping I have shared some useful insights which they are open for discussion and validation anytime.

Thanks forr this
LikeLike